¿De qué se trata?
Si alguna vez quisiste tener un ChatGPT privado, que corra en tu propio servidor, que no envíe tus datos a nadie, y que además pueda buscar en internet, consultar tu base de clientes o conectarse a WhatsApp, este proyecto es para vos.
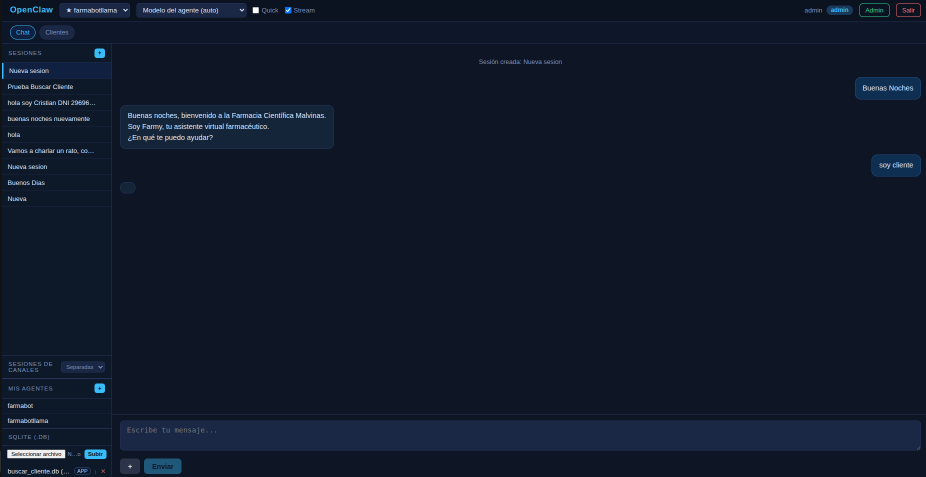
OpenClaw es una plataforma de IA conversacional completamente autoalojada. Funciona con Ollama para ejecutar modelos de lenguaje localmente (llama3.2, mistral, qwen2.5, phi4 y muchos más) y expone una API + interfaz web desde un contenedor Docker.



¿Qué puede hacer?
Múltiples agentes con personalidad propia
Podés crear agentes con rol, descripción, modelo y prompt de sistema distintos. Un agente “comercial” que conoce tu catálogo, un agente “técnico” que responde soporte, un agente “recepcionista” para tu chatbot. Cada uno con su configuración y herramientas independientes.
Herramientas ejecutables desde el chat
El agente puede usar herramientas reales durante la conversación:
🔍 web_search — busca en DuckDuckGo o SearXNG en tiempo real
🌐 web_fetch — lee y extrae el contenido de cualquier página web
🧮 calculator — evalúa expresiones matemáticas de forma segura
🕐 system_time — retorna fecha/hora con zona horaria configurable
📊 sqlite_query — consulta bases de datos SQLite que vos subís
👤 buscar_cliente — CRM: busca un cliente y su historial de compras
Todo esto sin salir del chat. El modelo decide qué herramienta usar y cuándo, en hasta 3 iteraciones.
CRM integrado para agentes comerciales
Cada usuario puede tener su propia base de datos de clientes en SQLite. El agente consulta automáticamente el historial cuando se menciona un cliente. La consola web permite gestionar clientes y compras con recordatorios de compras recurrentes.
Canales de mensajería
Un agente puede conectarse a WhatsApp Business, Telegram o exponer una Chatbot API para integraciones propias. Todo configurable desde el panel, sin tocar código.
Arquitectura en 30 segundos
Ollama (modelos LLM) ↕OpenClaw Middleware (Flask · SQLite · JWT) ↕Consola web + WhatsApp + Telegram + API REST
Dos contenedores Docker. Volúmenes persistentes. Un archivo .env para configurar todo.
Instalación
git clone https://github.com/Yupick/ollama_docker.gitcd ollama_dockercp .env.example .env # Configurar JWT_SECRET y modelo./stack.sh setup # Build + descarga del modelo./stack.sh start # Levantar el stack
Listo. Panel admin en http://localhost:5000/admin.html, consola de usuario en http://localhost:5000.¿Por qué self-hosted?
Privacidad total: los datos de tus clientes, tus conversaciones y tus documentos nunca salen de tu infraestructura
Sin costos de API: no pagás por token, el límite es tu hardware
Control total: elegís el modelo, ajustás los parámetros, habilitás o deshabilitás funciones
Sin vendor lock-in: si Ollama soporta el modelo, OpenClaw lo usa
Estado del proyecto
El proyecto está activamente en desarrollo con GitFlow. La versión v1.3.0 incluye herramientas ejecutables, CRM por usuario y correcciones de bugs. El historial completo está en CHANGELOG.md.
🔗 Repo: github.com/Yupick/ollama_docker
📦 Release: v1.3.0