Cada día somos testigos de titulares impactantes y vídeos falsos que recorren el mundo en segundos. Detrás de ese tsunami informativo, la inteligencia artificial juega un papel dual: alimenta la desinformación y, al mismo tiempo, ofrece herramientas para combatirla. En este artículo analizaremos cómo los Modelos de Lenguaje Grande (LLM) facilitan la detección de contenido falso, qué riesgos introducen los deepfakes y cuáles son las metodologías de verificación que marcan la diferencia.
El auge de la desinformación digital
La desinformación no es un fenómeno nuevo, pero la velocidad y el alcance de las redes sociales han multiplicado su impacto. Un estudio de Grinberg et al. (2019) reveló que aproximadamente el 6 % de los usuarios compartió noticias falsas durante la elección de 2016 en EE. UU., propagándolas hasta 10 veces más rápido que las genuinas. Esta capacidad de viralización ha llevado a gobiernos y plataformas a buscar soluciones basadas en IA para frenar el flujo de bulos.
Rol de los LLM en la detección de desinformación
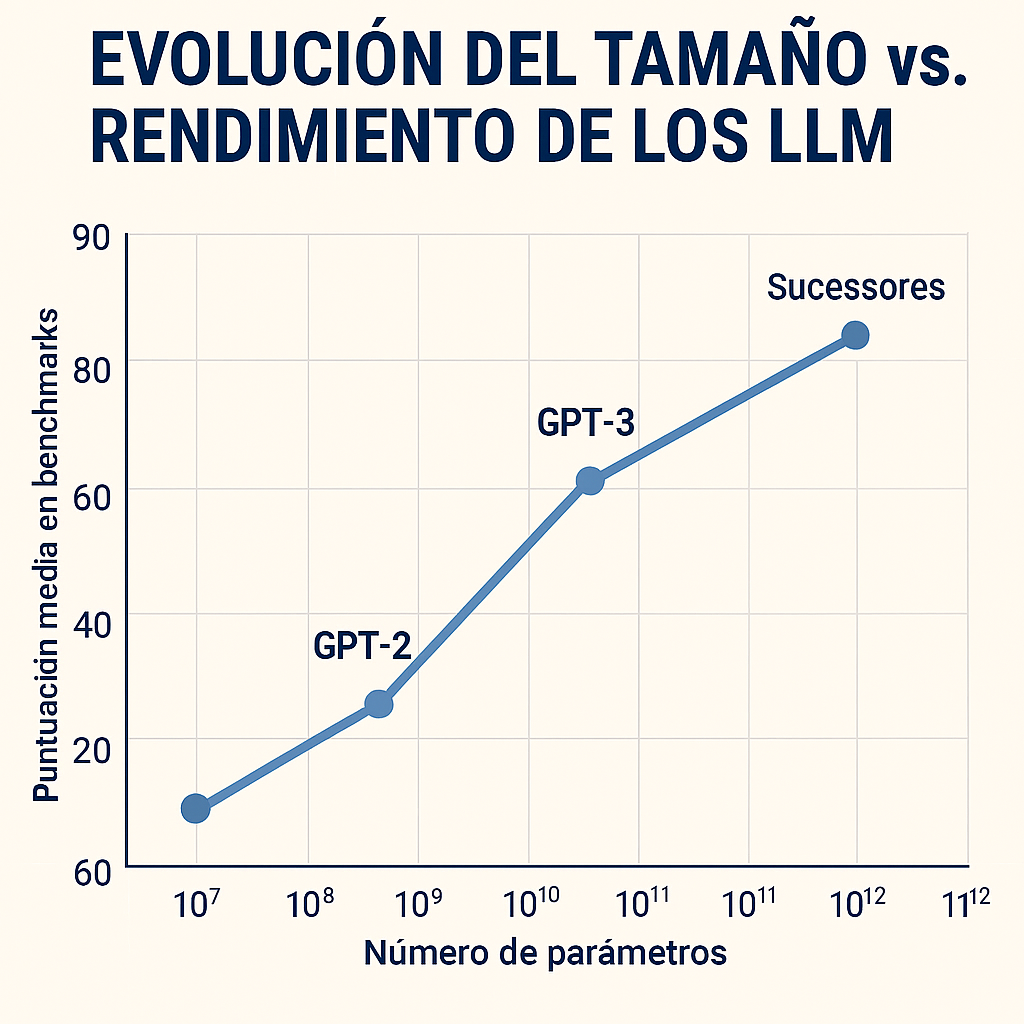
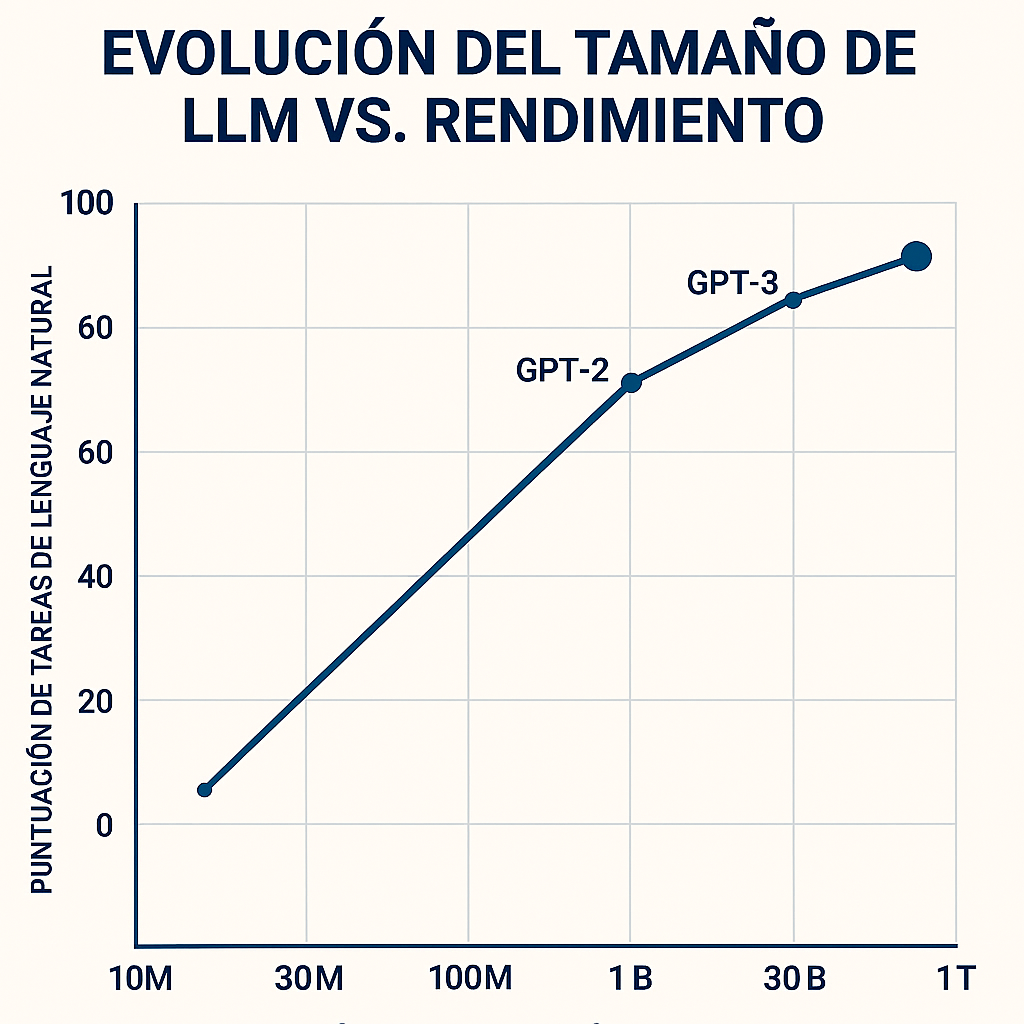
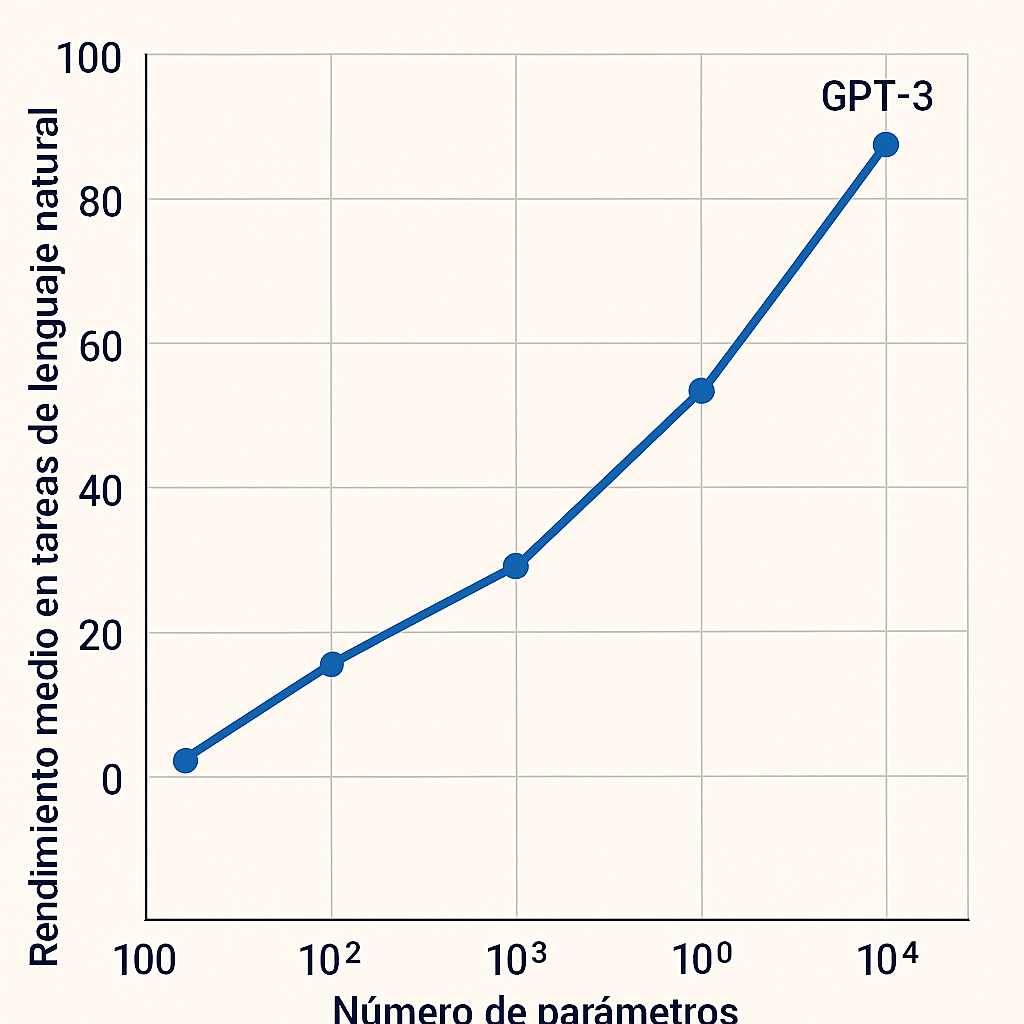
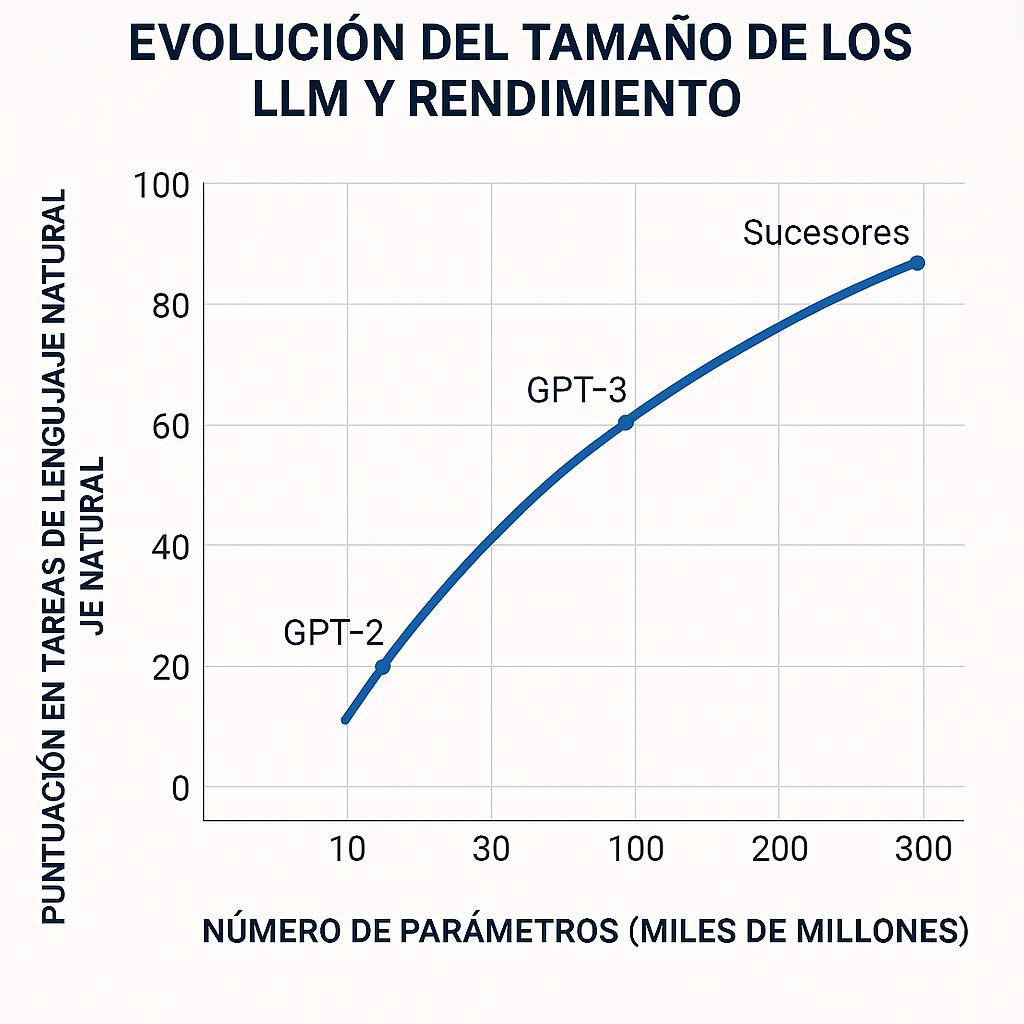
Los LLM, como GPT-4 o LLaMA, entrenados con cientos de miles de millones de parámetros, identifican patrones lingüísticos y anomalías estadísticas en textos sospechosos. Al procesar grandes volúmenes de publicaciones, estos modelos pueden asignar puntuaciones de credibilidad y señalar afirmaciones poco fiables (Westerlund, 2019).
- Detección de patrones: comparan la redacción con estilos periodísticos verificados.
- Clasificación de fuentes: jerarquizan información según la reputación histórica de los medios.
- Resumen de contexto: generan resúmenes contrastando múltiples fuentes para aportar distintos puntos de vista.
Este enfoque automatizado acelera la labor de los fact-checkers, pero no sustituye la verificación humana, esencial para evaluar matices culturales o errores de interpretación.
Deepfakes y sus implicaciones
Los deepfakes utilizan redes neuronales generativas para crear vídeos y audios falsos con rostros y voces casi indistinguibles de los originales. Según Chesney y Citron (2019), la combinación de GANs (Generative Adversarial Networks) y LLM abre la puerta a campañas de desinformación hiperrealistas:
- Suplantación de líderes: vídeos falsos que incitan al odio o al pánico.
- Fraude financiero: grabaciones apócrifas solicitando transferencias.
- Desacreditación de periodistas: vídeos manipulados para erosionar la confianza pública.
El desarrollo de detectores de deepfakes, basados en anomalías en parpadeo y reflexiones oculares, demuestra un primer paso, aunque los generadores avanzan a mayor velocidad.
Herramientas y métodos de verificación
- Fact-checking asistido por IA Plataformas como Full Fact y Factmata incorporan LLM para escanear texto y verificar datos en bases de conocimiento oficiales. Estos sistemas destacan afirmaciones clave y proponen enlaces a fuentes primarias.
- Detección de deepfakes
- Métodos basados en artefactos digitales: analizan inconsistencias en los píxeles y patrones de iluminación (Li et al., 2020).
- Análisis de metadatos: revisan firmas de edición en archivos multimedia.
- Cross-check colaborativo Comunidades de verificadores (e.g., First Draft) combinan IA y verificación manual. Los voluntarios contrastan fragmentos de vídeo, geolocalizan imágenes y rastrean cuentas origen.
- Sistemas de reputación Navegadores y extensiones (NewsGuard, Media Bias/Fact Check) asignan “semáforos” a medios según criterios de transparencia editorial y precisión histórica.
Retos y recomendaciones
- Sesgos algorítmicos: los LLM pueden reproducir prejuicios presentes en sus datos de entrenamiento (Bender et al., 2021).
- Velocidad vs. precisión: la carrera por detectar contenido falso en tiempo real puede sacrificar el rigor.
- Educación mediática: empoderar al usuario para que desconfíe de información anónima y verifique antes de compartir.
Recomendaciones prácticas:
- Implementar pipelines mixtos IA + verificación humana.
- Fomentar la transparencia en las entidades que desarrollan detectores.
- Promover la alfabetización digital desde edades tempranas.
¿Te preocupa la desinformación? Participa en nuestra encuesta y cuéntanos qué herramientas de verificación utilizas a diario. Ayúdanos a crear un ecosistema informativo más fiable.
Referencias
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623.
Chesney, R., & Citron, D. K. (2019). Deep fakes: A looming challenge for privacy, democracy, and national security. California Law Review, 107(6), 1753–1819.
Grinberg, N., Joseph, K., Friedland, L., Swire-Thompson, B., & Lazer, D. (2019). Fake news on Twitter during the 2016 U.S. presidential election. Science, 363(6425), 374–378.
Li, Y., Chang, M.-C., & Lyu, S. (2020). In Ictu Oculi: Exposing AI created fake videos by detecting eye blinking. arXiv.
Westerlund, M. (2019). The emergence of deepfake technology: A review. Journal of MultiDisciplinary AI Applications, 2, 165–181.
Desinformación #LLM #Deepfakes #FactChecking #InteligenciaArtificial #Tecnología #Verificación